브레인 소프트의 고해상도 스펙트로그램 : 1msec 시간 해상도와 1Hz 주파수 해상도
새로운 문제 인식 방법으로 음성 분야의 새로운 솔루션 제공!
브레인소프트는 사람의 청각 시스템의 동작 원리에 착안하여 시간 해상도와 주파수 해상도를 동시에 높이는 고해상도 스펙트로그램 추출 알고리듬(DJ Transform 특허 출원: 2019-0003620)을 개발하고, 개발한 알고리듬을 적용하여 음성인식과 화자인식 등에서 발생하는 다양한 문제점들을 해결하고 있습니다.
고해상도 스펙트로그램
기존 대비, 약 100배 이상의 고해상도
STFT 저해상도 스펙트로그램

- 주파수 해상도가 낮아서 주파수가 유사한 음성 구분이 어려움
- 자음 등 짧게 발음되는 음소를 다른 음소로부터 분리가 어려움
- 노이즈가 있으면 신호와 정보가 섞여서 분리가 어려움
DJ transform 고해상도 스펙트로그램
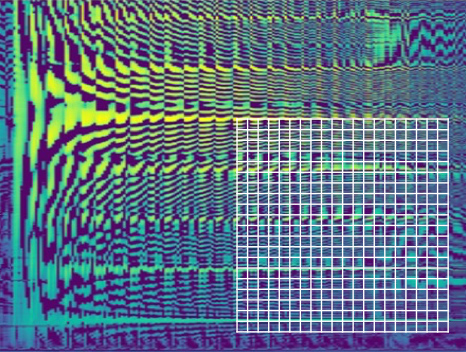
- 주파수 해상도가 높아서 유사한 발음 구분 가능
- 시간 해상도가 높아서 음소 발생 순서를 정밀하게 추출 가능
- 노이즈와 신호의 분리가 용이함
시간 해상도가 높아지면 음소들을 겹치지 않고 발생 순서대로 차례로 인식할 수 있게 되어서 각 음소의 인식 정확도를 높일 수 있고, 그 결과로써 음소 발생 순서를 정밀하게 추출할 수 있게 되어 음성인식 정확도를 높일 수 있게 됩니다. 주파수 해상도가 높아지면 유사한 발음 구분이 수월해지고 노이즈와 신호의 분리가 용이해서 노이즈 환경에서의 음성인식 정확도를 높일 수 있게 됩니다.
스펙트로그램 추출 알고리즘은 사운드 AI 성능에 영향을 주는 핵심 원천 기술
모든 사운드 데이터는 스펙트로그램으로 변환된 후 AI의 학습 데이터로 사용됩니다. 생성된 스펙트로그램은 사운드의 특징을 추출하는 데 사용되는 기본 데이터이며 스펙트로그램의 해상도에 따라서 소리의 특징 벡터의 정밀도가 결정됩니다. 따라서, 스펙트로그램 추출 기술은 AI의 기반기술로서 AI의 성능 및 효율에 영향을 주는 핵심 원천 기술 중 하나입니다.
고해상도 스펙트로그램 적용 시 기대효과
기존 STFT기반 엔진의 문제점
-
환경에 따른 음성 인식률의 급격한 하락
각종 노이즈에 따른 별도 학습 및 모델링 필수
음원이 먼 거리일 때, 인식률 저하
2명 이상이 동시에 말할 때 (Cocktail 파티 문제)
-
자음 인식 오류(짧은 단어)
AI 스피커, 가전, 자동차 등의 음성명령 인식 오류
-
신조어/사투리 인식 오류
잦은 데이터 확보 및 모델 갱신 필요
-
방대한 학습량의 필요
방대한 학습 데이터 제작/확보 비용 소요
-
화자인식 오류
화자 특징 추출, 중첩구간, 화자 변경 등에 인식성능 저하

고해상도 스펙트로그램 적용을 통한 문제 해결
-
세밀한 주파수 분석이 가능하여, 노이즈와 음성의 분리 정밀도 향상
시간 해상도가 높아서 짧은 시간 동안 발생하는 소리의 인식률 증가
음소 분리가 정밀하여 발음대로 문자열을 출력 가능하므로 신조어 인식률 증가
-
신조어 데이터수집 및 학습에 소요되는 비용 감소
-
음소 분리가 정밀하여 발음대로 문자열 출력이 가능하므로 소규모의 학습 데이터로 사투리 인식률 증가
-
발음구분이 정밀해지므로 기존 방법대비 적은 규모의 학습 데이터로도 동일한 인식률 달성 가능
-
음성 녹음 환경 의존성이 감소
(기존에는 환경 별 학습 데이터가 필요 → 회의실, 지하철, 버스, 거리, 카페 등) -
개인별 음성의 높낮이 측정 정밀도 향상
-
억양, 발음, 속도 등 개인별 음성 특성의 측정 정밀도 향상
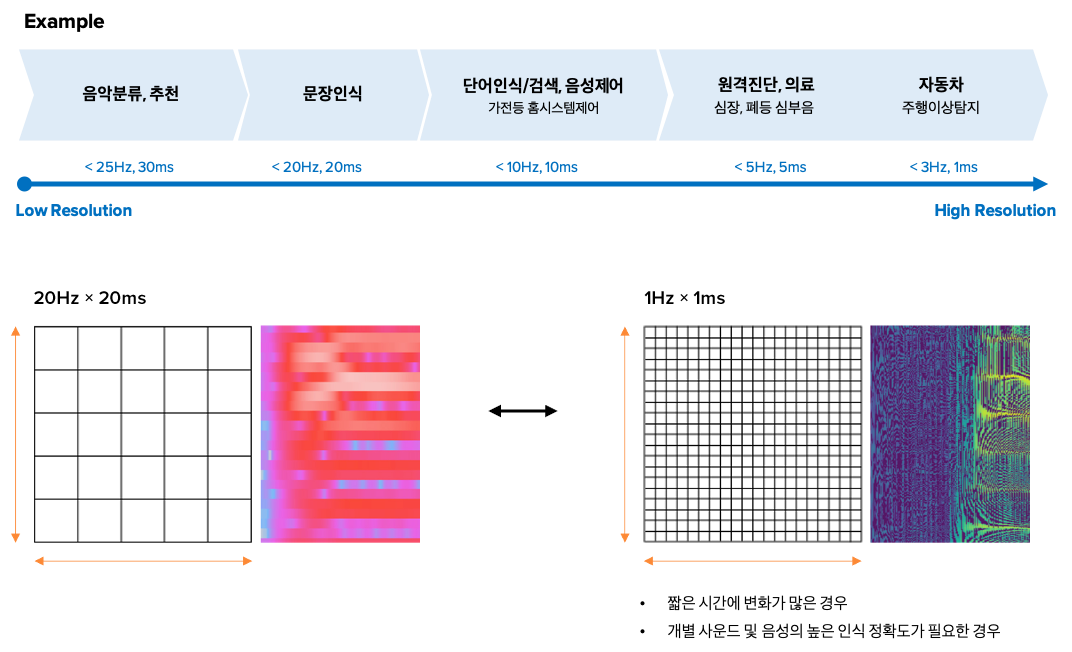
다양한 산업분야의 요구성능에 따른 유연한 해상도 적용
기존 Fourier Transform의 한계 Read More
STFT의 근본적 약점으로 인하여, AI의 성능에 한계를 가지고 있음 (시간 해상도와 주파수 해상도 간의 Trade-off 관계)
현재의 음성인식 AI 기술은 단시간 푸리에 변환 Short Time Fourier Transform(STFT)에 의해서 생성된 스펙트로그램을 입력으로 사용합니다. 그러나, STFT를 사용하면 생성된 스펙트로그램의 시간 해상도와 주파수 해상도가 trade-off 관계에 있어서 시간 해상도와 주파수 해상도를 동시에 높일 수 없는 한계가 발생합니다.
낮은 주파수 해상도
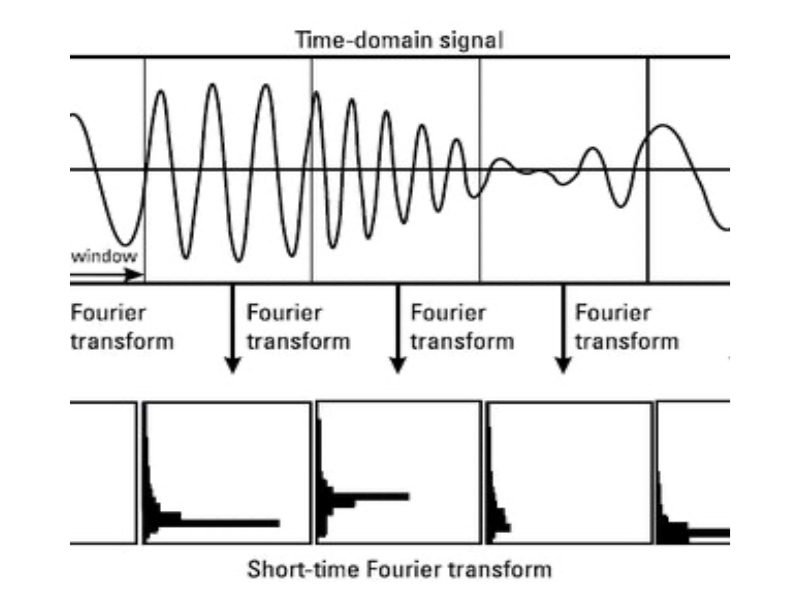
- 25msec 단위로 음성 신호를 처리
- 시간에 따른 음성 신호 변화를 주파수에 따른 세기로 변환
- 10msec마다 위의 작업을 적용해서 스펙트로그램 생성
* Rajmil Fischman. The Phase Vocoder: Theory and Practice. Organised Sound 2(2):127–145, 1997.
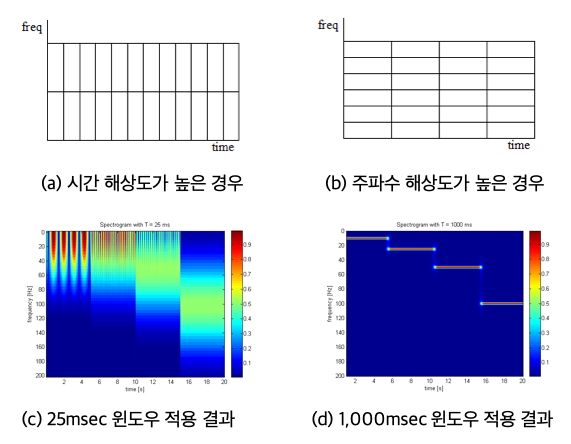
- 시간 해상도와 주파수 해상도가 서로 반비례 (그림 a, b)
- 시간 해상도가 25msec이면 주파수 성분이 넓게 퍼짐 (그림 c)
- 시간 해상도와 주파수 해상도 사이의 trade-off가 발생
* https://en.wikipedia.org/wiki/Short-time_Fourier_transform
다양한 시도와 경험을 통해서 25msec의 시간 해상도와 약 32Hz 주파수 해상도 결과를 사용하고 있지만, 이러한 해상도는 인간의 청각 시스템에 비교하면 매우 저해상도에 해당하는 것으로, 블러링된 정보를 사용하여 음성인식을 해야 하는 것과 같습니다.
25msec의 시간 해상도를 사용하면 짧게 발음되는 자음이나 연속적으로 발생하는 모음에 의해서 25msec내에 동시에 두 개의 음소가 들어가는 상황이 발생하게 됩니다. 이 상황에서의 음성인식은 주어진 단어를 구성하는 각 글자를 서로 다른 사람이 동시에 발음한 후 해당 단어를 맞추는 이구동성 게임에서 단어를 맞추려는 시도에 해당합니다.
노이즈가 존재하고 음성 주파수와 노이즈 주파수가 유사할 때 생성된 스펙트로그램의 주파수 해상도가 낮으면 두 개의 주파수 성분이 합쳐져서 음성과 노이즈의 분리가 원천적으로 안되는 상황이 발생하게 됩니다. 따라서, STFT로 생성된 스펙트로그램을 사용하여 음성인식을 수행하게 되면 높은 정확도의 결과를 생성하기 어려우며, 특히 노이즈가 있거나 발음이 불명확하면 그 정확도는 급격히 떨어지게 됩니다.
저해상도 스펙트로그램의 문제점 예시 Read More
인간의 청각시스템이 소리를 저해상도 스펙트로그램으로 변환한다고 가정할 때
우리가 음악 감상을 한다면?
낮은 주파수 해상도로 인하여, 표현 가능한 주파수 종류가 제한되어서 우리는 음정이 뭉개진 음치의 노래를 듣게 됩니다. 또한 낮은 시간 해상도로 인하여 아래 그림과 같이 가사 발음이 뭉개지므로 가사를 알아듣기 어렵게 됩니다. 하지만 인간의 청각 시스템은 1Hz, 1msec 까지도 구분이 가능하기 때문에 우리는 정확한 음정과 발음으로 노래를 감상할 수 있습니다. 따라서, 현재 음성인식 기술은 발음이 부정확한 음치의 노래를 듣고 원곡 가사를 받아쓰고 있는 것입니다.

저해상도 스펙트로그램

파란 사각형은 하나의 시점에 들리는 발음을 의미함. 하나의 파란 사각형에 두 글자가 걸쳐 있는 상황 발생. 따라서, 동시에 두 개의 소리를 듣는 상황이 발생하므로 발음을 정확히 인지하기 어려움.
고해상도 스펙트로그램

회색 사각형은 최소 시간 단위를 의미하고 빨간 사각형은 하나의 시점에 들리는 발음을 의미함. 여러 개의 회색 사각형으로 하나의 발음만을 포함하는 빨간 사각형을 구성할 수 있으므로 하나의 빨간 사각형에 두 글자가 걸쳐 있는 상황 회피 가능. 따라서, 한 순간에 하나의 발음만 들을 수 있으므로 발음을 정확하게 인지할 수 있음.
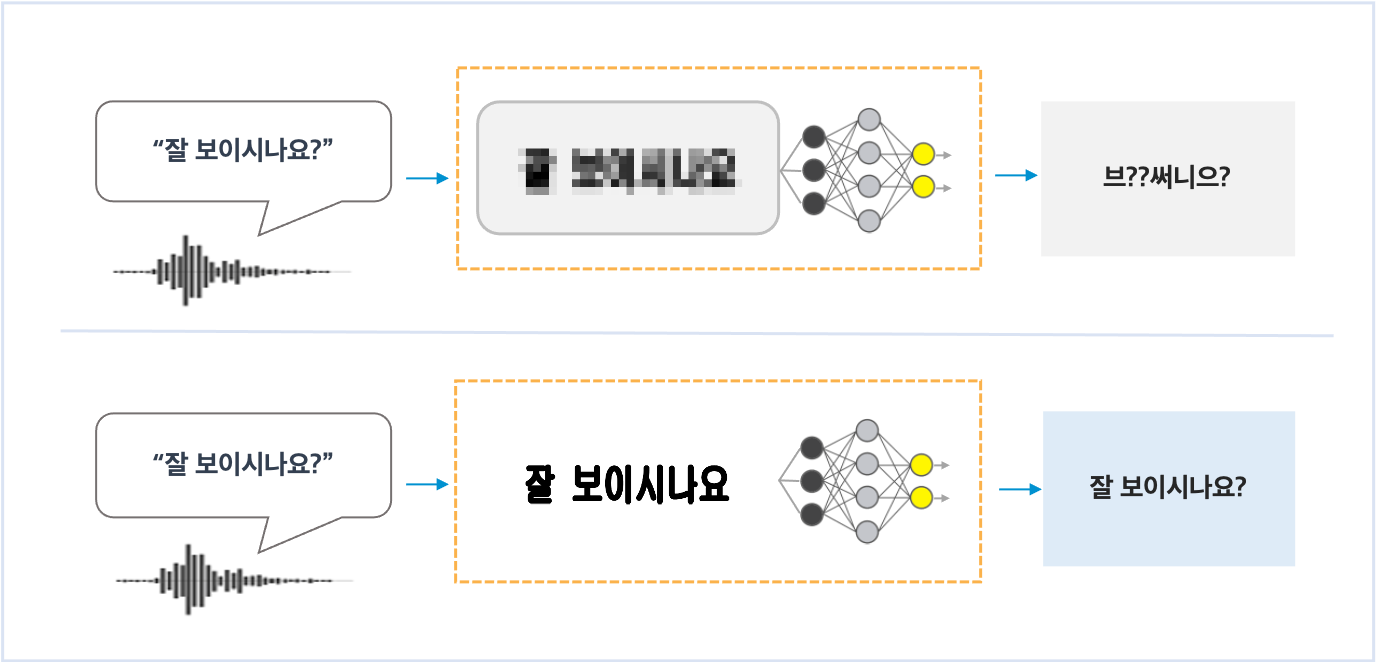
저해상도 스펙트로그램을 이용한 음성인식과 블러링된 문자 인식의 유사성 Read More
저해상도 스펙트로그램은 마치 고품질의 소리 데이터를 블러링한 것과 같습니다. 블러링된 글자를 정확하게 읽는 것이 어려운 것처럼 저해상도 스펙트로그램 기반에서는 음성 인식이 어렵게 됩니다.
많은 다양한 형태로 블러링된 문자열을 읽어 본 사람은 그렇지 않은 사람에 비해서 블러링된 문자 인식 정확도가 높을 수는 있는 것처럼 많은 학습 데이터가 있으면 저해상도 스펙트로그램을 사용하더라도 음성 인식률을 높일 수 있음을 예상할 수 있습니다. 그러나, 스펙트로그램 생성 단계에서 손실된 정보는 이후 단계에서 복원이 불가하므로 정확도 향상에는 반드시 한계가 있습니다.
브레인소프트 기술은 고해상도 스펙트로그램을 사용하므로 기존 음성인식의 정확도 한계를 극복할 수 있으며, 학습 데이터 규모 측면에서도 강점을 가지고 있습니다.
기존 Short-Time Fourier transform의 한계로 인한 AI의 한계 Read More
한계에 도달한 사운드 및 음성 인식
STFT의 정확도 한계
-
불확정성의 원리
시간해상도와 주파수 해상도간의 trade-off 관계
-
스펙트로그램 생성 단계에서 정보 손실 발생
이후 단계에서 복원이 안됨
-
경험에 의한 타협
25msec(시간) & 32Hz(주파수)
인식률의 한계
-
단어 인식 오류
짧은 자음(25msec 이하)의 경우, 주파수 분석 한계로, 자모 순서 추출 정확도 한계 발생. AI 스피커, 가전, 자동차 등의 음성 인터페이스에 적용 어려움 (Toy 앱 수준의 낮은 신뢰도)
-
높은 화자인식 오류
여러 개의 주파수 성분이 겹치는 경우에는 분석 불가
-
사투리나 신조어 인식 오류
학습 DB 양으로 승부하는 상황
-
방대한 학습 DB의 양으로 승부
단어 인식의 한계를 극복하지 못해, 확률 게임인 문장 인식률 확보에 집중
-
그럼에도 모든 문장을 맞출 수는 없는 상황
투입비용(데이터량)과 성능이 임계점에 도달한 상황 → 비효율 구간
