Brainsoft's high-resolution spectrogram: 1msec time resolution and 1Hz frequency resolution
With the new insight, a new solution in the field of sound!
Inspired by how the human auditory system works, Brainsoft has developed a high-resolution spectrogram extraction algorithm (DJ Transform patent application: 2019-0003620) that simultaneously increases time and frequency resolution. By applying this algorithm, we have been solving various problems of speech recognition and speaker recognition.
High-Resolution Spectrogram
Higher resolution than a conventional spectrogram
STFT: Low-Resolution Spectrogram

- Difficult to discriminate voices with similar frequencies
- Difficult to separate shortly pronounced phonemes such as consonants from other phonemes
- If a noise exists, the noise and a signal are mixed to be difficult to separate them
DJ Transform: High-Resolution Spectrogram
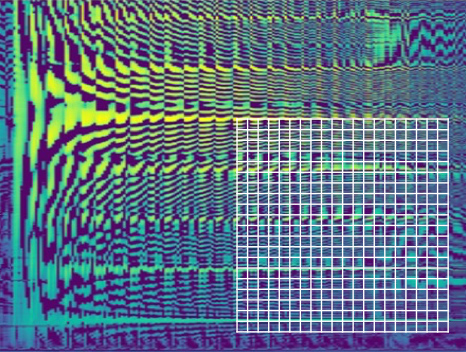
- Distinguish similar pronunciations
- Precise extraction of phoneme occurrence sequence
- Feasible to separate noise and signal
As the time resolution improves, phonemes can be recognized in the order of occurrence without overlapping, thereby increasing the accuracy of recognition of each phoneme. As the frequency resolution improves, it becomes easier to distinguish similar pronunciations and to separate signals from noise, thereby increasing the accuracy of speech recognition in a noisy environment.
Spectrogram is a core algorithm that affects the performance and efficiency of AI
All sound data is converted into a spectrogram to be used as a training data set for AI. The generated spectrogram is essential data for extracting features of the sound, and the resolution of the spectrogram determines the precision of the feature vector of the sound. Therefore, the spectrogram extraction technology is one of the core technologies that affects AI's performance and efficiency.
Expected effect of using high-resolution spectrograms
Problems of the existing
STFT-based engine
-
Rapid decline in speech recognition accuracy depending on the environment
Different model required for each noise environment
Accuracy decreases for a distant sound
Accuracy decreases for overlapping voices (example of a cocktail party)
-
Consonant recognition error (a short word)
Voice command recognition error (AI speakers, home AI, car AI, etc.)
-
New word / dialect recognition error
Frequent data acquisition and model update required
-
Need for a vast amount of training data
Expenses for producing/gathering vast training data
-
Speaker recognition error
Decreased recognition performance (speaker feature extraction, overlapping section, speaker change, etc.)

Problem solving
by applying high-resolution spectrogram
-
With a precise frequency analysis, separation accuracy improves for noise and speech
With high time resolution, recognition accuracy improves for short sounds
With the accurate phoneme separation, phonemes are extracted in the pronunciation sequence to increase the recognition accuracy of new words
-
Reduce the cost for collecting and learning new words
-
With the accurate phoneme separation, the phonemes are extracted in the pronunciation sequence to increase the dialect recognition accuracy with small-scale learning data
-
With the accurate pronunciation classification, achieve equal recognition accuracy with a smaller amount of training data
-
Reduced dependency on an environment noise (no training data required for each environment – conference room, subway, bus, street, cafe, etc.)
-
Improve pitch estimation accuracy of individual voices
-
Improve measurement accuracy of individual voice characteristics such as intonation, pronunciation, and speed
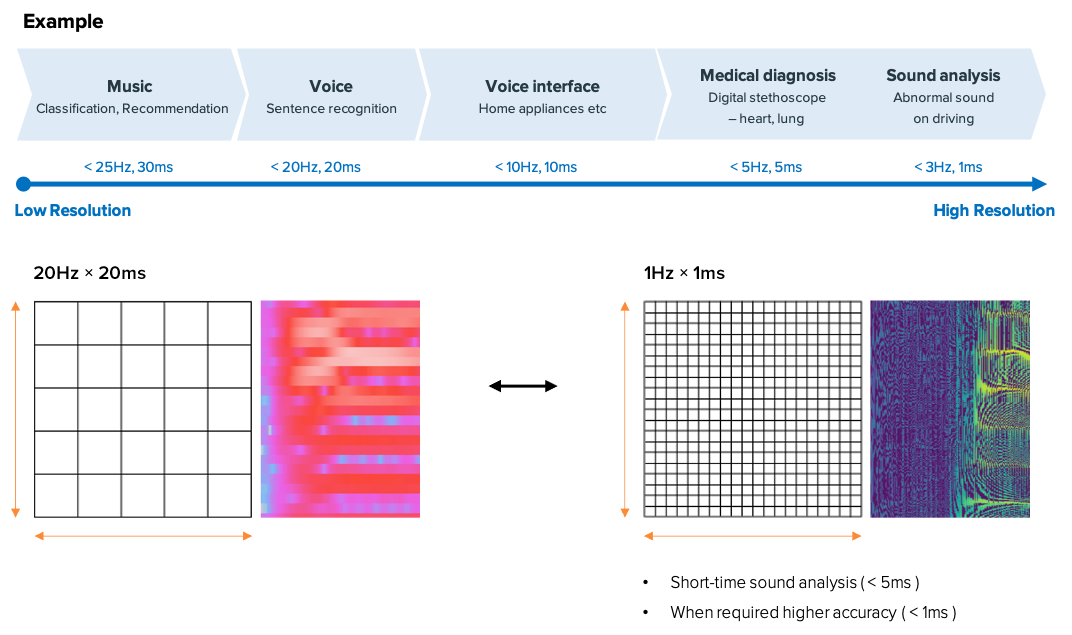
Flexible resolution choice for each application
Limitations of the Fourier transform Read More
Existing AI performance is limited due to weakness of STFT (trade-off between time and frequency resolution)
The current speech recognition AI technology uses the spectrogram generated by the Short Time Fourier Transform (STFT) as input data. However, the STFT window size parameterizes the trade-off between time and frequency resolution. Therefore, if STFT is used, there is a limitation in that the time and frequency resolution cannot be simultaneously increased.
Low resolution on frequency domain
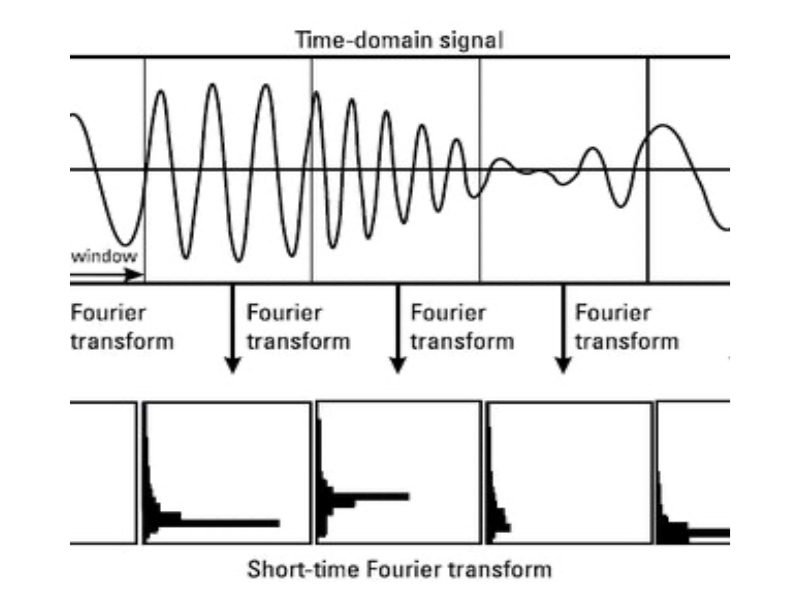
- Voice signal processing in units of 25 msec
- Frequency extraction from voice signals within each unit
- Spectrogram generation by applying the above operation every 10msec
* Rajmil Fischman. The Phase Vocoder: Theory and Practice. Organised Sound 2(2):127–145, 1997.
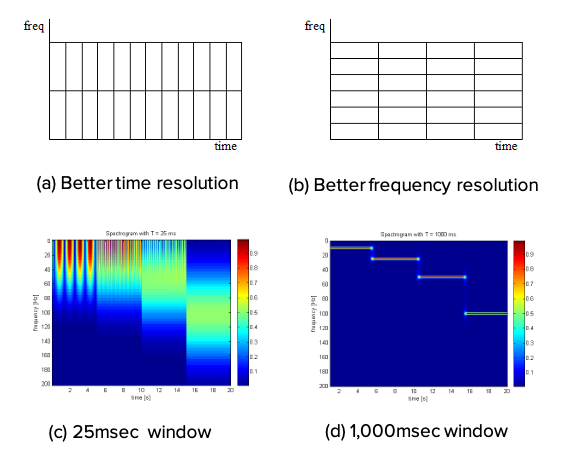
- Time resolution and frequency resolution are inversely proportional to each other (Fig. a, b)
- If the time resolution is 25msec, the frequency component spreads widely (Fig. c)
- Conflict between time resolution and frequency resolution occurs
* https://en.wikipedia.org/wiki/Short-time_Fourier_transform
The time resolution of about 25 msec and the frequency resolution of about 32Hz is widely used for spectrogram generation through various trials and experiences. However, these resolutions are very low compared to the human auditory system. This means that blurred information is used for speech recognition.
If you use a time resolution of 25msec, the situation where two phonemes are simultaneously located within 25msec occurs due to short pronounced consonants or consecutive vowels. The speech recognition in this situation corresponds to an attempt to recognize a word when several people take charge of each syllable constituting the word and simultaneously pronounce each assigned syllable.
If noise is present and a frequency resolution for a voice is low, when the voice frequency and the noise frequency are close to each other, the two frequency components are merged, resulting in the situation where the separation of the voice and the noise is not fundamentally possible. Therefore, if speech recognition is performed using the spectrogram generated by STFT, it is difficult to produce highly accurate results. Especially if there is noise or pronunciation is unclear, the accuracy drops sharply.
Examples of comparison between low-resolution and high-resolution Read More
Assuming that the human auditory system converts a sound into a low-resolution spectrogram, what happens when we listen to music?
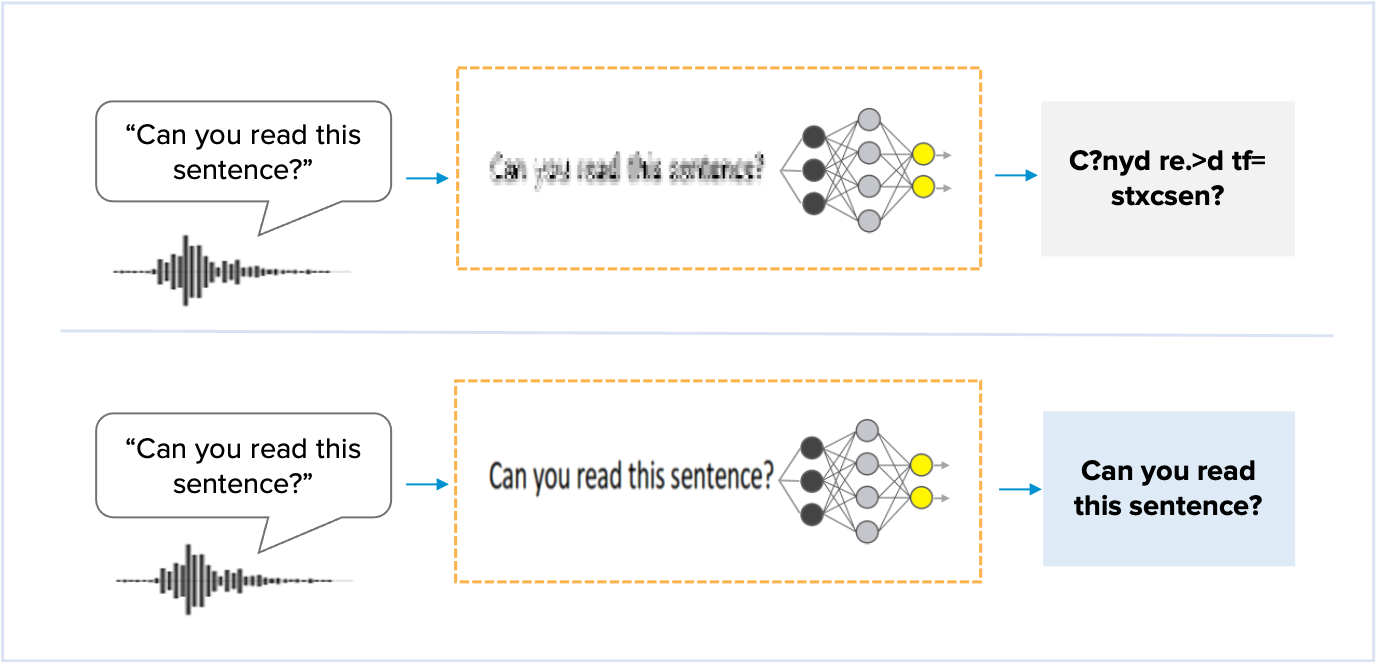
Due to the low-frequency resolution, the number of frequencies that can be expressed is limited so that it sounds like a bad singer is singing. Also, due to the low temporal resolution, the pronunciation of the lyrics is crushed as shown in the picture below, making it difficult to understand the lyrics.
However, the human hearing system can distinguish even 1Hz and 1msec, so we can enjoy singing with accurate pitch and pronunciation. From the above comparison, we can know the current voice recognition technology corresponds to listening to singing with an incorrect pitch and pronunciation to dictate the lyrics of the song.

Low Resolution Spectrogram

The blue box denotes the pronunciation heard at one point in time. There exists a situation where two letters are overlapped in one blue square. Therefore, it is difficult to accurately recognize the pronunciation because a situation occurs where two sounds are heard at the same time.
High Resolution Spectrogram

The gray square denotes the minimum unit of time and the red square denotes the pronunciation heard at one point in time. A red square containing only one pronunciation can be composed of multiple gray squares, so it is possible to avoid situations where one red square contains two letters. Therefore, you can hear only one pronunciation at a time, so you can accurately recognize the pronunciation.
The similarity between blurred text recognition and speech recognition using a low-resolution spectrogram Read More
A low-resolution spectrogram corresponds to the result of blurring a high-resolution spectrogram of sound. Just as it is difficult to accurately read blurred characters, speech recognition becomes difficult if a low-resolution spectrogram is used.
For example, people who have seen many blurred characters in various forms can more easily recognize blurred characters than people who are not used to doing so. Similarly, we can expect that, if there is a lot of training data, the speech recognition accuracy can be improved even though a low-resolution spectrogram is used. However, since the information lost in the spectrogram generation step cannot be restored in a later step, there should be a limit to improving accuracy.
Since Brainsoft technology uses a high-resolution spectrogram, it can overcome the accuracy limitation resulting from the information loss in the step of spectrogram generation of the current speech recognition. The technology also has strengths in terms of the scale of training data.
Limitations of speech recognition AI due to Short-Time Fourier Transform Read More
Sound and speech recognition confronted with limits
Limitation of STFT accuracy
-
The principle of uncertainty
The trade-off between time and frequency resolution
-
Information loss in the spectrogram generation
-
Compromise by experience
25msec and 32Hz
Limitation of recognition rate
-
Word recognition error
If several phonemes including a consonant occur in the short duration such as 25msec, the accurate extraction of a sequence of phonemes is limited
Not enough accuracy to be applicable to voice I/F in a critical situation (Toy application level)
-
High speaker recognition error
If multiple components overlap in frequency, the analysis is infeasible
-
Dialect or new word recognition error
Competing by data quantity
-
The massive amount of training data is used for Deep Learning to overcome the limitation
Because of the limitation of word recognition, the focus is on sentence recognition
-
Nevertheless, not all sentences can be recognized
-
Almost reached the critical point (Inefficiency): data cost and performance
