Through our technology in a high-resolution spectrogram, Brainsoft resolves problems in the field of AI voice and is growing rapidly by exploiting its competitive edge across international markets.
The performance of the pre-processing step can be improved by high-resolution frequency extraction. As a result, the overall performance and efficiency of the speech-related artificial intelligence system can be improved.
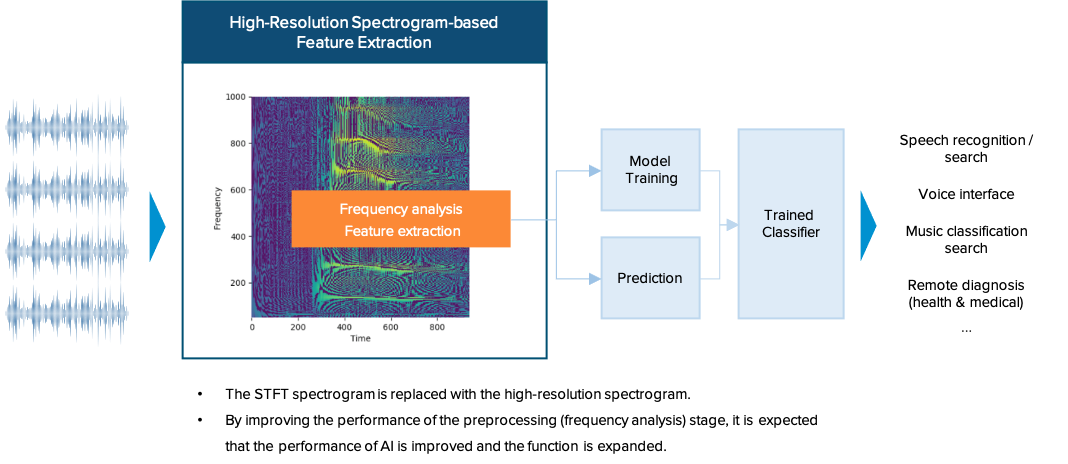
Given a voice, a high-resolution spectrogram is extracted. Then, speech recognition is performed with a more precise time unit of the spectrogram by extracting 1) the probability distribution of phonemes in each unit time or 2) phoneme time intervals which consist of several time units. Since the situations where more than one phoneme co-occur in one-time unit are reduced, it is possible to increase the accuracy of speech recognition.
The image below is an example that shows the probability distributions of phonemes in a unit of time. If the unit of time is large, there may be more than one phoneme in the time unit with a high probability of occurrence. The smaller the unit of time, the smaller the probability of having two phonemes in one unit of time.
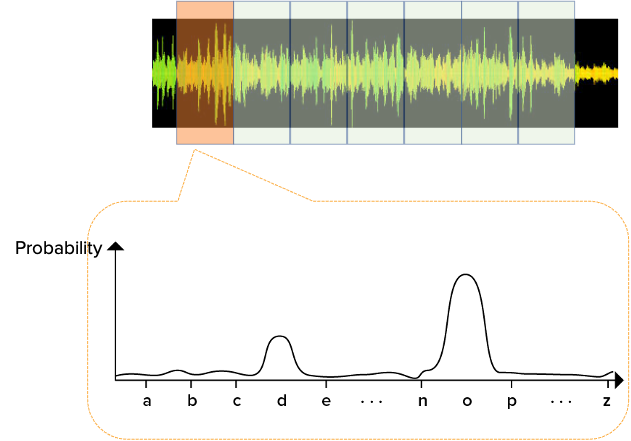
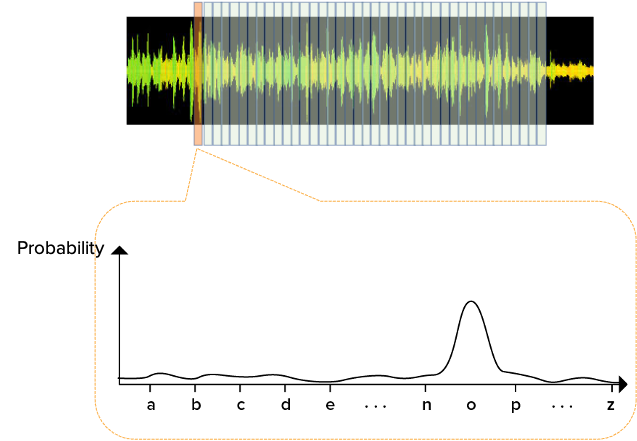
If the unit of time is large, it becomes similar to the situation of recognizing a word where several people simultaneously speak each syllable constituting the word. For example, given the word "recognition", if four different people pronounce each of the syllables "re", "cog", "ni", and "tion", respectively, and they speak sequentially, it will sound exactly like "recognition". However, if four people speak simultaneously, it becomes difficult to hear "recognition". If we utilize a high-resolution spectrogram in the scenario, the accuracy of speech recognition can be improved.
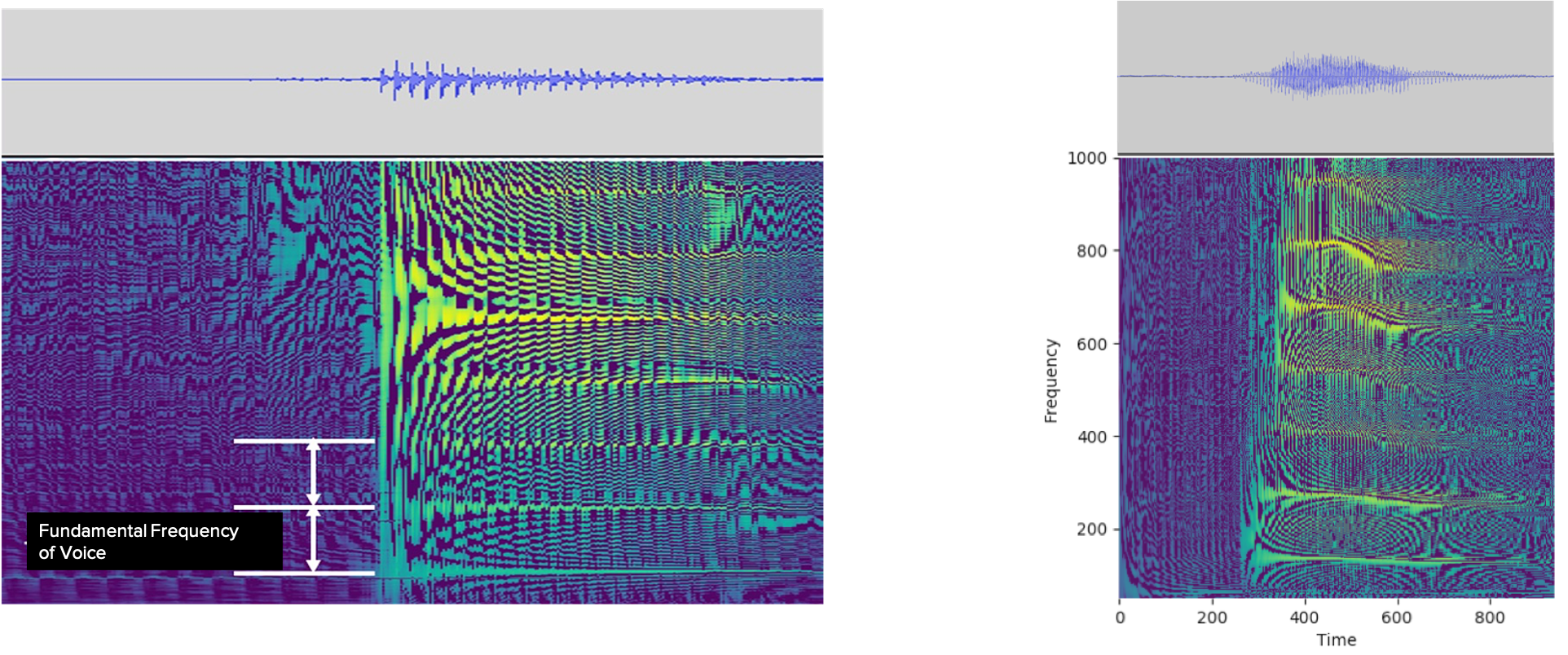
A high-resolution spectrogram allows for precise extraction of voice pitch which distinguishes human voices, syllable duration, or changes in voice tone. Therefore, if speaker recognition is performed with the precisely extracted information, we can expect to improve the accuracy of the speaker recognition.
The pitch of a voice is determined by the fundamental frequency of the voice. As shown in the figure below, the fundamental frequency of a voice is generally higher for women than for men and higher for children than for adults.
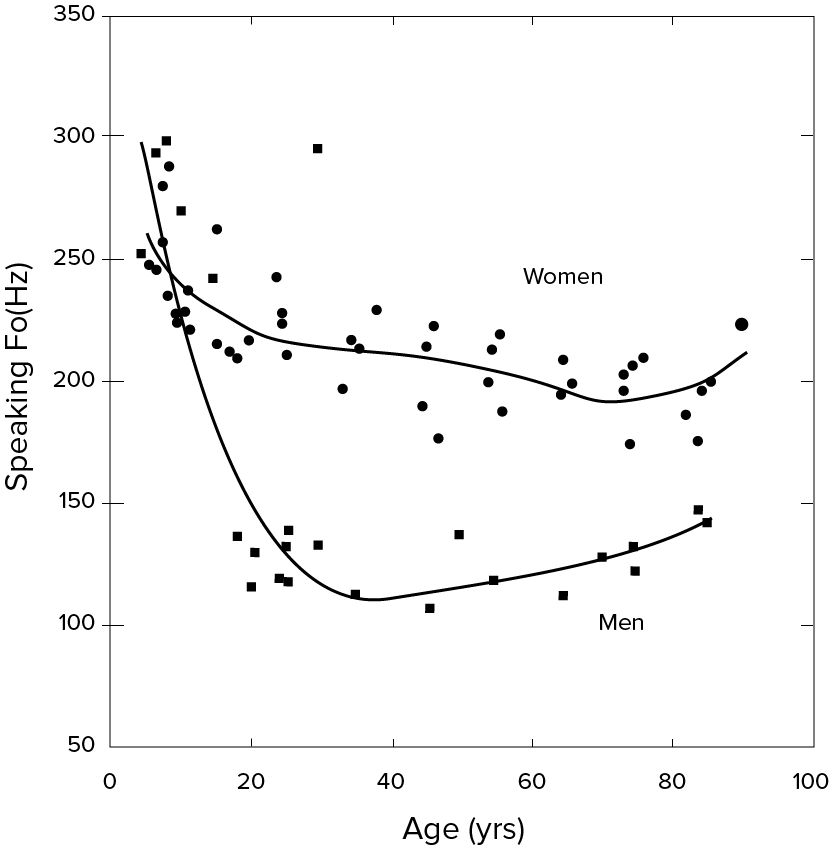
Using a high-resolution spectrogram, you can precisely extract the fundamental frequency and tone changes of a voice. Especially in a noisy environment, the advantage of using a high-resolution spectrogram is more evident than the conventional method.
| Patent title | Date | Application (registration) number | |
|---|---|---|---|
| KR | Frequency extraction method by DJ transformation | 2019.1.11 | 10-2019-0003620 |
| PCT | Frequency extraction method by DJ transformation | 2019.11.26 | PCT/KR2019/016347 |
| KR | Fundamental frequency extraction method based on DJ transformation | 2020.10.05 | 10-2164306 |
| KR | Method of extracting pure tones constituting compound tones | 2020.7.21 | 10-2020-0089961 |
| PCT | Fundamental frequency extraction method based on DJ transformation | 2020.11.12 | PCT/KR2020/015910 |
| PCT | Method of extracting pure tones constituting compound tones | 2021.2.10 | PCT/KR2021/001807 |
| US | Frequency extraction method using DJ transform | 2021.2.12 | US17/268,444 |
| US | Fundamental frequency extraction method using DJ transform | 2021.4.23 | US17/288,459 |
